

Its
set up roughly like this.

Creating the volumes
I
am going to start raw and just make the volumes from scratch.
For details on volume types see https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/#types-of-volumes [1]
Create and start volume-one
|
> sudo gluster
volume create volume-one
replica 2
192.168.0.200:/data/brick1 192.168.0.201:/data/brick1 |
Create and start volume-two
|
> sudo gluster
volume create volume-two
disperse 3 redundancy 1 192.168.0.200:/data/brick2
192.168.0.201:/data/brick2 192.168.0.202:/data/brick2 |
Now check out the satus
|
> sudo gluster
volume info |
|
Volume Name:
volume-one |
Mount the drives
I have a client server already set up see http://www.whiteboardcoder.com/2023/03/glusterfs-etcfstab-mount-options.html [2] (Basically the glusterfs client is installed on it)
Now I am just going to edit the /etc/fstab and mount the drives I just made in GlusterFS
First let me make the mount points.
|
> sudo mkdir
/volume_one_client |
Now edit /etc/fstab
|
> sudo vi
/etc/fstab |
Put the following in it
|
#defaults = rw, suid, dev, exec, auto, nouser, and async. |
Now mount them
|
> sudo mount -a |
And check them out
|
> df -h |

Change the ownership of the mounts to my user
|
|

Looks good.
Let me put some files in them
Run the following command to create 20 files of 10MiB that have random data filling them
|
> seq -w 1 20 |
xargs -I{} dd if=/dev/urandom of=/volume_one_client/random_{}.txt count=1 bs=10M |

Looks
good.
Kill the 00 machine
OK,
now I am going to kill the 01 machine and test the outcome.
The /etc/fstab mounts at the 00 machine, but once it is mounted the FUSE knows about the other two glusterFS servers and it will remain mounted even thought 00 no longer exists. However if you have to re-mount them you will need to update the /etc/fstab if 00 is still down or in this case gone.
So
I am going to go the harsh way and turn this machine off and rebuild an entire
new one.
|
|

Now write to both mounts
|
|

Working
as expected.
Now let me see what the cluster says about itself.
Run this command from one of the remaining glusterFS servers
|
|

It is disconnected, as expected
You can run the following to see the health of the volume itself
|
|

|
|

Now
I do not see a nice single command that will tell me if a volume only has X
redundancy left. I have enough info with
this and other commands to calculate that.
So I guess if I want more fancy details I would have to create that myself
with some simple script which I will not do yet, but good to know I could…
Add some more files
While its broke I want to add some more files…. A lot more
Make 20 1 GiB files per volume (this may take a while
|
> seq -w 1 20 |
xargs -I{} dd if=/dev/urandom of=/volume_one_client/big_random_{}.txt count=1 bs=1G |
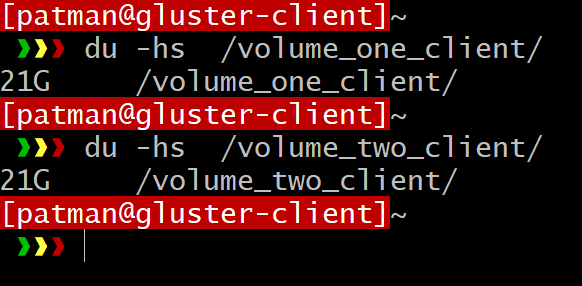
|
> du -hs
/volume_one_client |
Create a new Machine from scratch
I am not going to go into any detail on the first creation of the server itself. The server is an ubuntu 22.04 with a secondary drive attached to it and mounted. Now I just need to install glusterfs like I did in this post http://www.whiteboardcoder.com/2023/02/installing-glusterfs-103-on-ubuntu-2204.html [3]
So let’s get it set up
OK run the following commands to trust this and get it updated
|
> sudo add-apt-repository
ppa:gluster/glusterfs-10 |
Now update
|
> sudo apt
update |
Check version
|
> apt show
glusterfs-server |
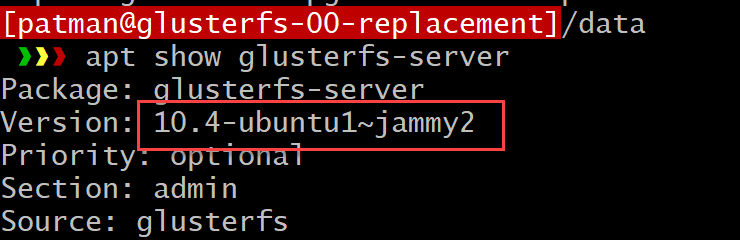
10.4 I will take that!
Now install glusterfs
|
> sudo apt
install glusterfs-server |

Start GlusterFS up
Start it up
|
> sudo systemctl
start glusterd |
Check its status
|
> sudo systemctl
status glusterd |
Now enable it so it starts after a reboot
(You will notice in the above image it is currently disabled)

|
> sudo systemctl
enable glusterd |
Check the status
|
> sudo systemctl
status glusterd |
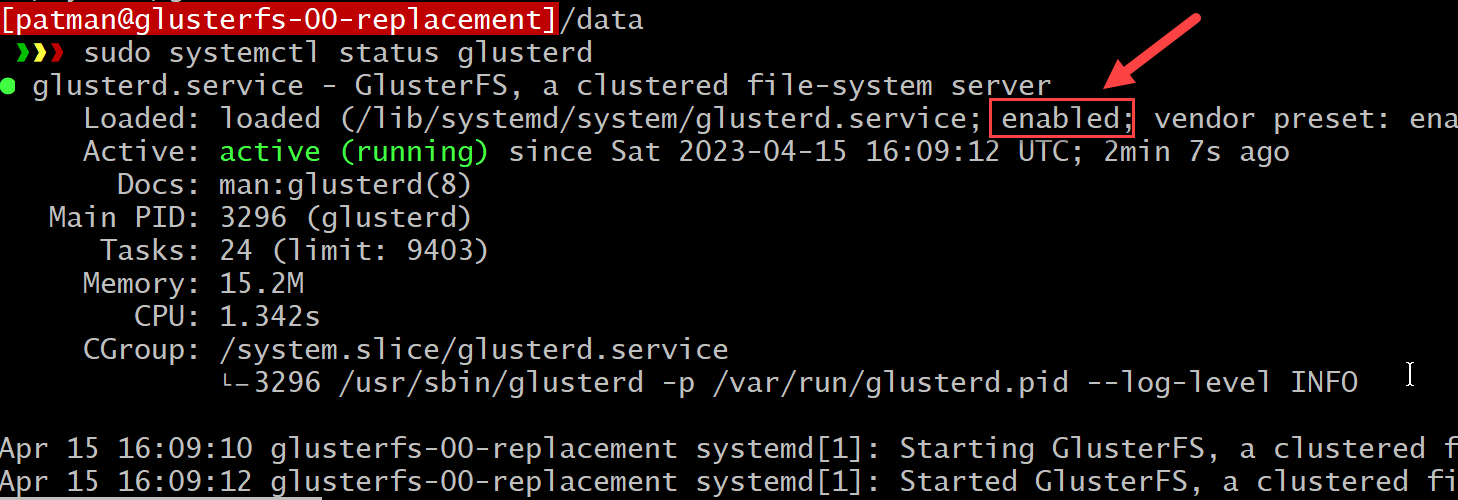
It is enabled, now reboot
|
> sudo reboot |
Check if its running after a reboot
|
> sudo systemctl
status glusterd |

And we are happy now.
New Server Pre set up status
This GlusterFS server has not joined its peers and it has no bricks in the /data volume
|
> lsb_release -a |

Also If I check peers and volumes from this new server.
|
> sudo gluster
peer status |

Just wanted to capture my before status and show nothing is connected and no volumes (as far as the new gluster server is concerned).
How Do I get it to replace the old machine?
Its easy enough to add a new peer to the old cluster and make a new volume that uses the old two still existing glusterFS servers and this new one. But how do I add this one in and take over the responsibilities of the old server we are replacing?
I obtained some insite on how to do this from this web post. https://docs.rackspace.com/support/how-to/recover-from-a-failed-server-in-a-glusterfs-array/ [4] and also a little help from chatgpt and also some direct notes from glusterFS https://docs.gluster.org/en/latest/Administrator-Guide/Managing-Volumes/#shrinking-volumes [5]
The following will work with Replicate or Distributed Replicate Volume recovery
To do this process properly this takes 2 steps.
Replicate
volume-one fix
Step 1.
Run the following from one of the still
peered GlusterFS Server
(of course put your new glutserFS server IP)
|
> sudo gluster
peer probe 192.168.0.220 |
![]()
Step 2.
Replace the old bricks of the failed server
with new bricks on the new server. (.200
being the old failed server and .220 being the new replacement in this example)
(of course put your new glutserFS server IP)
|
> sudo gluster
volume replace-brick volume-one
192.168.0.200:/data/brick1
192.168.0.220:/data/brick1
commit force |
![]()
Success!
Now to monitor its progress run the following command.
|
> sudo gluster
volume heal volume-one info |



I see the number count down as it heals

Dispersed volume-two fix
Now to do this for the dispersed volume I
have
Step 1.
I do not need to run this step since it was done in the last volume fix.
Run the following from one of the still
peered GlusterFS Server
(of course put your new glutserFS server IP)
|
> sudo gluster
peer probe 192.168.0.220 |
![]()
Step 2.
Replace the old bricks of the failed server
with new bricks on the new server. (.200
being the old failed server and .220 being the new replacement in this example)
(of course put your new glutserFS server IP)
|
> sudo gluster
volume replace-brick volume-two
192.168.0.200:/data/brick2 192.168.0.220:/data/brick2 commit force |
![]()
Success!
Now to monitor its progress run the following command.
|
> sudo gluster
volume heal volume-two info |



Clean up
OK now to clean up we just need to double check and make sure none of our volumes still expect the old server 192.168.0.200 and then we can remove it from the peer cluster.
|
> sudo gluster
volume info |
|
Volume Name: volume-one Volume Name: volume-two |
Now 192.168.0.200 listed 😊
Now remove it from the cluster
|
> sudo gluster
peer status |

Now remove it
|
> sudo gluster
peer detach 192.168.0.200 |

Ahh
and good note
Fix mounts
Now clean up my /etc/fstab on my clients since they are trying to mount via the old glusterFS machine
|
> sudo vi
/etc/fstab |
![]()
Change
to
![]()
And reboot to make sure it remounts just fine
|
> sudo reboot
now |

Looks good 😊
Well
I think that worked out now all my stuff is happy.
References
[1] Replicated GlusterFS Volume
https://docs.gluster.org/en/latest/Quick-Start-Guide/Architecture/#types-of-volumes
Accessed 04/2023
[2] GlusterFS /etc/fstab mount
options GlusterFS/NFS testing in Ubuntu 22.04
http://www.whiteboardcoder.com/2023/03/glusterfs-etcfstab-mount-options.html
Accessed 04/2023
[3] Installing GlusterFS 10.3 on
Ubuntu 22.04 and get it working
http://www.whiteboardcoder.com/2023/02/installing-glusterfs-103-on-ubuntu-2204.html
Accessed 04/2023
[4] Recover from a failed server
in a GlusterFS array
https://docs.rackspace.com/support/how-to/recover-from-a-failed-server-in-a-glusterfs-array/
Accessed 04/2023
[5] Managing GlusterFS Volumes
https://docs.gluster.org/en/latest/Administrator-Guide/Managing-Volumes/#shrinking-volumes
Accessed 04/2023
No comments:
Post a Comment